服务器、超算使用教程
# 服务器、超算使用教程
# 服务器、超算介绍
# master
- Linux 系统:Ubuntu 22.04,内核:5.19.0-43-generic
- root 权限:无 ;无法使用 apt、apt-get、dpkg、snap 命令安装程序
- 任务调度系统:Slurm
- CPU:Intel Xeon Platinum 8369B,共 64 核;CPU 信息查看:
cat /proc/cpuinfo - GPU:2 $\times$ 24G RTX 3090;调用 GPU 时只能一整块调用,显存自动分配;GPU 信息、使用情况查看:
nvidia-smi - Intel 套件:Intel-oneAPI 2022.1.0
- 内存:共 512G;内存信息查看:
cat /proc/meminfo;内存使用情况查看:free -h - 数据存储:较大体积的数据(master 本地或超算上的)可以放到
${HOME}/storage /home/share目录,不同用户可将临时共享文件放此,所有用户可删除文件,但文件夹需其所有者才能删除,因此建议将文件夹进行打包压缩再放到 share 目录中
- master 上已安装的程序/软件:
cat /opt/bin/README查看
# Code Function
ave....................Get the averages of data columns in a file
bave...................Get the block averages of data columns in a file
binave.................Get the bin averages of data columns in a file
crysinfo...............Get the crystalline symmetry info for an xyz file
cumsum.................Get the cummulative sum of data columns in a file
d2p....................Dump2phonon, get dynamical matrix from a lammps trajectory file
dos2th.................Get thermal info from phonon DOSes.
dumpana................Analyze the lammps dump file
find-min-pos...........Find the location (line #) of a minimum value within a column data
find-val-pos...........Find the location of a given value within a column data
get-col-num............Get the column number of a word in the first line of the file.
getpot.................Get vasp potential for desired elements.
gsub...................Submit GPU jobs.
hist...................Get the histogram of a data file.
histjoin...............To join multiple files from hist.
latgen.................To generate the position file for selected crystals.
lmp....................LAMMPS
mathfun................To perform simple math calculations.
ovito..................To visualize atomic configurations.
phana..................To analyze binary file from fix-phonon.
posconv................To convert formats of pos files
run....................To find the locations of running jobs.
spave..................To get the spatial average from data columns in a file
submit.................To submit CPU jobs.
v6.gam.................vasp.6.3.0.gam
v6.ncl.................vasp.6.3.0.ncl
v6.std.................vasp.6.3.0.std
vacf...................To measure phonon DOS based on velocity-velocity autocorrelation function method
vasp...................vasp.5.4.4.std
vasp.5.gam.............vasp.5.4.4.gam
vasp.5.std.............vasp.5.4.4.std
vasp.6.gpu.............vasp.6.3.0.std.gpu (OpenACC)
vasp.6.gpu.gam.........vasp.6.3.0.gam.gpu
vasp_gam...............vasp.5.4.4.gam
vaspkit................Toolkit for vasp calculations.
vasp_std...............vasp.5.4.4.std
viscal.................To calculate shear viscosity based on Green-Kubo method
vmd....................To visualize md trajectories
- GPU 信息及使用情况查看:
nvidia-smi、gpustat;gpustat - Python (opens new window)
# 持续查看 GPU 使用情况
watch -d2 nvidia-smi
gpustat -i 2
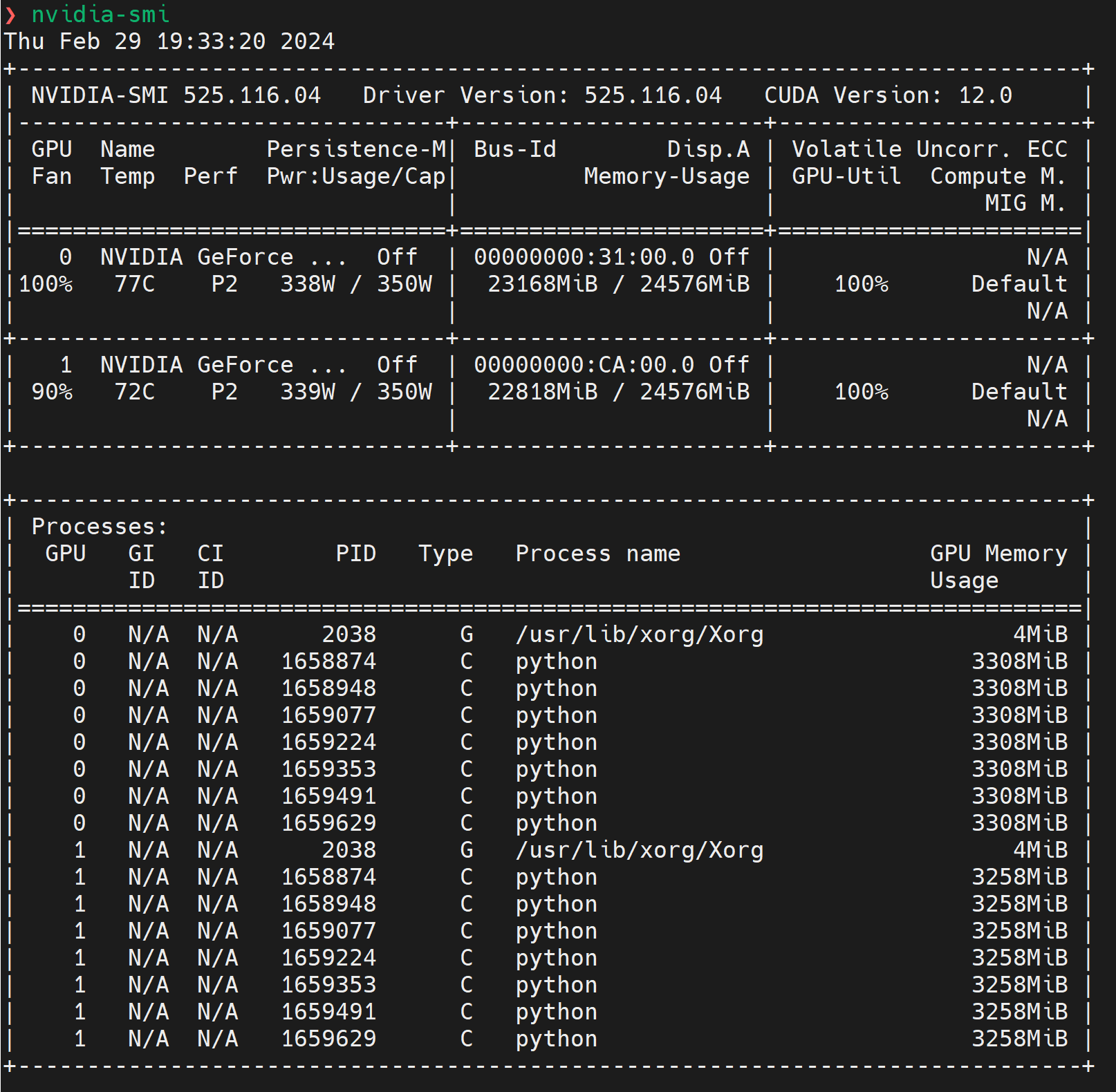
输出信息解读:两个 GPU 都在高负载运行(GPU 利用率 100%,温度分别为 77 摄氏度和 72 摄氏度),并且接近其功率上限。GPU 上的内存几乎被完全利用,表明运行的进程(主要是 python)正在积极使用 GPU 资源。
NVIDIA-SMI 版本和驱动版本:显示
nvidia-smi工具的版本为 525.116.04,NVIDIA 驱动版本也是 525.116.04,CUDA 版本是 12.0。这对于确保软件兼容性是重要的信息。GPU 列表:
- GPU 0 和 GPU 1:系统中有两个 NVIDIA GeForce 系列的 GPU。具体型号没有完全显示,但可以看出系统识别到两块 GPU 卡。
- Persistence-M:显示 GPU 的持久模式是否开启,这里都是关闭(Off)的。
- Bus-Id:显示 GPU 在系统总线上的唯一标识符,可以用于特定应用配置。
- Disp.A:显示是否用作显示输出,这里都是关闭(Off)的。
- Volatile Uncorr. ECC:显示易失性未校正的 ECC(错误校正码)错误,这里显示为 N/A(不适用),可能是因为 GPU 不支持 ECC 或未启用。
- Fan:GPU 风扇速度,以百分比表示。
- Temp:GPU 温度,单位是摄氏度。
- Perf:性能状态,P2 表示当前在一种性能状态。
- Pwr:Usage/Cap:当前功率使用量和功率上限,单位是瓦特。
- Memory-Usage:GPU 内存使用情况,包括当前使用量和总量,单位是 MiB。
- GPU-Util:GPU 使用率,以百分比表示。
- Compute M.:计算模式,默认是 Default。
进程:列出了在每个 GPU 上运行的进程,包括:
- PID:进程 ID。
- Type:进程类型,G 表示图形,C 表示计算。
- Process name:进程名称。
- GPU Memory Usage:进程使用的 GPU 内存量。
# manager
- Linux 系统:Ubuntu 16.04;内核:4.15.0-120-generic
- root 权限:无 ;无法使用 apt、apt-get、dpkg、snap 命令安装程序
- 任务调度系统:PBS
- CPU:Intel Xeon E5520、Intel Xeon E5630(node 9)、Intel Xeon E5-2620(node 11);共 100 核,共 12 个节点(node1~11 + manager;其中 node2,6,7,8 经常 down)
- GPU:Matrox Electronics Systems Ltd. MGA G200eW WPCM450、XGI Technology Inc. XG20 core(前两者主要用于服务器的视频输出和基本图形处理任务)、2 $\times$ 4.6G NVIDIA Tesla K20m(node 11)
- 内存:登录、manager 节点约 4G;node 11 约 16G;node 1, 3-5 约 24G;node 9-10 约 16G;内存使用情况查看:
free -h - Intel 套件:Composer XE 2015
# 超算
- Linux 系统:Centos 7.7.1908(Pi); 8.3.2011(思源一号)
- root 权限:无;无法使用 yum 命令安装软件程序
- 任务调度系统:Slurm;Pi、ARM、思源一号提交的任务在任一平台都可以看到
- CPU、内存:超算中的 CPU 核有内存配比限制
- GPU:超算的 GPU 队列很难排到
- 程序/软件:Pi 的一些基础程序的版本比思源一号旧许多;查看:
module av - Pi 和 ARM 用户目录相同
- sylogin1 登录节点占用率较高,比其他(2-5)卡,是超算断开连接,vim 使用卡顿的可能原因之一;超算的登录节点为随机分配,应尽量避免登录到 sylogin1
# VASP 赝势目录路径
- Pi mseklt 用户目录中的 VASP 赝势与思源和 manager 上的有些不同,相比之下,前者不全。
/work/backup/.vasp_pot/ # master
/opt/.vasp_pot # manager
$HOME/.sjtu_mgi/.vasp.pot # 思源一号 mseklt
$HOME/opt/VASP/VASP_PSP # Pi mseklt
# 服务器、超算登录
# SSH 登录
- 通过 SSH 登录集群 - 上海交大超算平台用户手册 Documentation (opens new window)
- 超算平台的 SSH 端口均为默认值 22,
-p 22可省略
# manager
ssh [email protected] -p 312
# master
ssh [email protected] -p 313
# 思源一号
ssh [email protected]
# Pi(cpu 队列)
ssh [email protected]
# Pi(centos 队列)
ssh [email protected]
# ARM
ssh [email protected]
# 终端 SSH 免密登录
无需输入用户名和密码即可登录,还可以作为服务器的别名来简化使用。免密登录需建立从远程主机(集群的登录节点)到本地主机的 SSH 信任关系。建立信任关系后,双方将通过 SSH 密钥对进行身份验证。
在本地主机上生成的 SSH 密钥对,输入以下命令,持续 Enter 即可;将在
~/.ssh(或C:\User\username\.ssh) 路径下生成密钥对文件id_rsa和id_rsa.pub;将id_rsa.pub的内容(注意字符之间只有一个空格,复制后需注意)添加到远程主机的~/.ssh/authorized_keys文件中。
ssh-keygen -t rsa
密钥对生成方式有 ssh-keygen 和 putty(ppk 格式,WinSCP 软件密钥验证需该格式),其中后者可通过 Mobaxterm 软件中 tool 工具中的 MobaKeyGen 来生成(在空白处乱按加快生成速度;将生成的公钥保存成 file.pub,私钥保存成 file.ppk)。
设置服务器别名:编辑或创建
~/.ssh/config(或 `C:\User\username.ssh\config
Host alias
HostName
User
Port
IdentityFile
具体示例:
Host Manager
HostName 202.120.55.11
User username
Port 312
IdentityFile ~/.ssh/id_rsa
Host Master
HostName 202.120.55.11
User username
Port 313
IdentityFile ~/.ssh/id_rsa
Host Pi
HostName pilogin.hpc.sjtu.edu.cn
User username
Port 22
IdentityFile ~/.ssh/id_rsa
Host SiYuan
HostName sylogin.hpc.sjtu.edu.cn
User username
Port 22
IdentityFile ~/.ssh/id_rsa
设置完成后,只需输入以下内容即可实现服务器、超算 SSH 登录:
ssh Manager
ssh Pi
ssh SiYuan
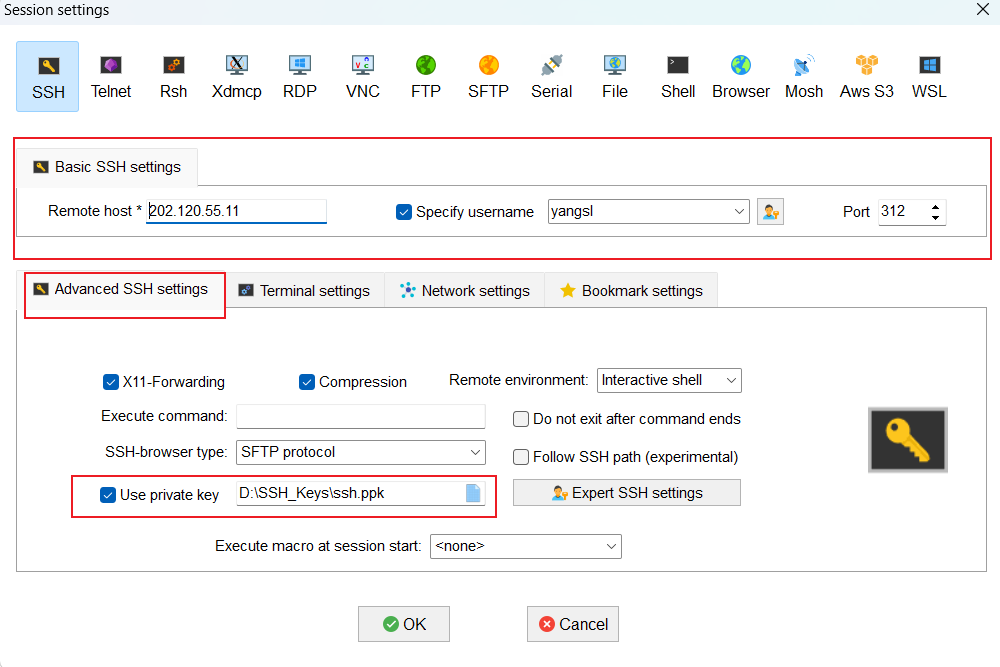
# 客户端免密登录
常用软件:MobaXterm、Tabby(学校有定制版) 等。
免密登录操作:将
id_rsa私钥文件所在路径添加到 Use private key 选项中(Bookmark settings 选项可以将默认的 Session name 改成自己想要的别名)。
# VSCode 免密登录
安装 Remote Development 扩展,如上面的
~/.ssh/config内容已设置好,会自动识别设置好的主机名(config 文件所在路径可自定义)。VSCode 远程连接 manager(机子较老,10 余年历史) ,有时会导致其负载过高而崩溃,不建议长时间连接;vscode 远程连接 master(2023 年 5 月配置)暂无相关问题。
在超算上使用 python 插件中的 pylance 语言服务器(LSP)以及 jupyter 插件,常会出现 pylance 崩溃的问题(Pi 稍微稳定些),因为超算的登录节点资源有限,建议将 pylance 换成 jedi(功能不及 pylance),会稍微稳定些;建议不在超算平台上使用 jupyter notebook。master 暂无相关问题。
# 任务准备、提交、检查
# Slurm 任务调度系统
Slurm 作业调度系统 - 上海交大超算平台用户手册 Documentation (opens new window)
常用命令:
sbatch- 任务提交squeue- 查看排队任务状态scancel- 删除任务scontrol- 查看任务参数sinfo- 查看集群状态
节点状态:
drain- 节点故障alloc- 节点在用idle- 节点可用down- 节点下线mix- 节点部分占用,但仍有剩余资源
作业状态:
R- 正在运行PD- 正在排队CG- 即将完成CD- 已完成
# 提交任务
sbatch job.slurm
# 查看作业参数
scontrol show job
scontrol show job JOB_ID
# 参数包括
UserId|WorkDir|JobState|JobId|JobName|NumNodes|NumCPUs|StdErr|StdOut|Command|RunTime
# 查看特定队列
sinfo --partition=64c512g
# PBS 任务调度系统
- manager 为此作业调度系统。
- 常用命令:
qsub- 提交任务;qdel- 取消任务 submit命令是孔老师写的一个 PBS 任务提交脚本。-nc参数含义:不将文件复制到计算节点中;推荐用带-nc参数的命令。- 提交任务命令会自动生成对应的
PBS.batch脚本;当提交的任务出错时,修改PBS.batch脚本内容,之后可使用qsub PBS.batch命令提交任务。
# VASP 任务提交命令
submit -nc -n 8 vasp
submit -n 8 vasp
# LAMMPS 任务提交命令
submit -nc -n 8 lmp -in in.file
submit -n 8 lmp -in in.file
manager 中与 PBS 相关的一些 alias 设置
# 查看 q 相关命令 alias
alias | grep ^q
# q 相关命令均由 qstat 延伸
alias q='qstat -u yangsl'
alias qq='pestat'
alias qa='qstat -a'
alias qn='qstat -u yangsl|wc -l|awk '\\''{if ($1>0) print "Number of jobs by yangsl: " $1-5; else print "Number of jobs by yangsl: 0"}'\\'';qstat -a|wc -l|awk '\\''{print "Number of jobs by all: " $1-5}'\\'''
qstat- 查看所有任务的状态;q- 查看自己任务的状态;qa- 查看所有任务的状态(比 qstat 显示的信息更多一些);qq- 查看计算节点的状态(excl- 正在运行;free- 空闲;down- 出现故障);run- 查看自己任务的结果输出路径和信息;qn- 查看自己提交任务的数量和 manager 目前已提交的任务总数;ssh node02- 连接计算节点;任务到了截止时间后程序会终止,只会输出error和out文件,可以通过ssh node节点到计算该任务的节点中去,在scratch目录中可以找到该任务计算的结果;- 计算时间:
Elap Time为实际时间(小时: 分);Req'd Time为截止计算时间(240 小时);Time Use为实际时间 * 节点数。
# 超算队列介绍
- 超算队列内存情况
arm128c256g 每核2G内存 arm
64c512g 每核8G内存 siyuan
cpu 每核4G内存 pi
small 每核4G内存 pi
dgx2 每核6G内存 pi
**huge 每核35G内存 pi
192c6t 每核31G内存 pi**
cpu,small和dgx2队列作业运行时间最长7天,huge和192c6t最长2天。作业延长需发邮件申请,附上用户名和作业ID,延长后的作业最长运行时间不超过14天。
- 队列资源选择
资源如何选择?
交我算HPC+AI平台采用 CentOS 的操作系统,配以 Slurm 作业调度系统,所有计算节点资源和存储资源,均可统一调用。
若是大规模的 CPU 作业,可选择 CPU 队列或思源一号64c512g队列,支持万核规模的并行;
若是小规模测试,可选 small 队列或思源一号64c512g队列;
GPU 作业请至 dgx2 队列或思源一号a100队列;
**大内存作业可选择 huge 或 192c6t 两种队列**。
- 192c6t 和 huge 大内存队列,核数有一定要求,且排队时间较长
192c6t 队列
sbatch: error: The cpu demand is lower than 48. Please submit to huge or cpu partition.
sbatch: error: Batch job submission failed: Unspecified error
huge 队列
sbatch: error: The cpu demand is lower than 6. Please submit to small partition.
sbatch: error: Batch job submission failed: Unspecified error
- 超算收费情况(2023.05.30)
交我算平台集群总费用为CPU,GPU和存储费用之和。费率标准如下:
CPU 价格:0.04元/核/小时(Pi 2.0集群 cpu/small/huge/192c6t/debug 队列)
0.05 元/核/小时(思源一号集群 64c512g 队列)
0.01元/核小时(arm128c256g队列)
GPU 价格:2 元/卡/小时(dgx2队列 V100 GPU)
2.5 元/卡/小时(思源一号 a100队列 A100 GPU)
免费存储 3 TB,超出部分 200 元/TB/年(存储按天扣费)
每个新账户赠送价值 300 元的积分,供免费试用
module avail/av # 查看超算预部署软件模块
module av [MODULE] # 查看具体模块
module load [MODULE] # 加载相应软件模块
module list # 列出已加载模块
module purge # 清除所有已加载软件模块
module show [MODULE] # 列出该模块的信息,如路径、环境变量等
查看 module load 相关软件模块的 lib 和 include 路径方法:
module load boost 相关版本后,使用 module show boost 命令可以查到 boost 的 lib 库位置,使用 grep -rn "libboost_python" /path/to/lib/* 命令检索相应的库文件
思源一号克隆 Github repo(或 wget 下载网络文件) 速度慢或无法进行;Pi 则正常。
解决方案:在计算节点上运行(有时也还是不稳定)或使用 Github 增强 - 高速下载 (opens new window) 油猴插件,选择合适的 URL 进行克隆。
计算节点是通过 proxy 节点代理进行网络访问的,因此一些软件需要特定的代理设置。需要找到软件的配置文件,修改软件的代理设置。
# 查看代理
echo $http_proxy $https_proxy $no_proxy
git、wget、curl 等软件支持通用变量,代理参数设置为:
# 思源一号计算节点通用代理设置
https_proxy=http://proxy2.pi.sjtu.edu.cn:3128
http_proxy=http://proxy2.pi.sjtu.edu.cn:3128
no_proxy=puppet,proxy,172.16.0.133,pi.sjtu.edu.cn
# π2.0计算节点通用代理设置
http_proxy=http://proxy.pi.sjtu.edu.cn:3004/
https_proxy=http://proxy.pi.sjtu.edu.cn:3004/
no_proxy=puppet
Python、MATLAB、Rstudio、fasterq-dump 等软件需要查询软件官网确定配置参数:
### fasterq-dump文件,配置文件路径 ~/.ncbi/user-settings.mkfg
# 思源一号节点代理设置
/tools/prefetch/download_to_cache = "true"
/http/proxy/enabled = "true"
/http/proxy/path = "http:/proxy2.pi.sjtu.edu.cn:3128"
# π2.0节点代理设置
/tools/prefetch/download_to_cache = "true"
/http/proxy/enabled = "true"
/http/proxy/path = "http://proxy.pi.sjtu.edu.cn:3004"
### Python需要在代码里面指定代理设置,不同Python包代理参数可能不同
# 思源一号节点代理设置
proxies = {
'http': 'http://proxy2.pi.sjtu.edu.cn:3128',
'https': 'http://proxy2.pi.sjtu.edu.cn:3128',
}
# π2.0节点代理设置
proxies = {
'http': 'http://proxy.pi.sjtu.edu.cn:3004',
'https': 'http://proxy.pi.sjtu.edu.cn:3004',
}
### MATLAB
# 思源一号节点代理设置
proxy2.pi.sjtu.edu.cn:3128
# π2.0节点代理设置
proxy.hpc.sjtu.edu.cn:3004
注意:
- 队列一般不设置独占节点(不能加
#SBATCH --exclusive) - 超算平台无法安装 OVITO,可视化平台有 OVITO,按小时收费
- 登录密码输错 5 词,需等待一段时候才能再次登录
# 任务提交示例
以下任务提交脚本代码使用的思源一号中的 64c512g 队列;超算中有许多不同版本的程序,可根据自身需求
module load相应版本的程序
SBATCH 相关参数
#SBATCH --job-name=vasp_job
#SBATCH --account=wen
#SBATCH --time=01:00:00
#SBATCH --nodes=1
#SBATCH --ntasks=24
#SBATCH --ntasks-per-node=1
#SBATCH --mem=50GB
#SBATCH -o %j.out
#SBATCH -e %j.err
#SBATCH --exclusive
# VASP
- 思源一号 VASP
#!/bin/bash
#SBATCH -J vasp
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
module load vasp/5.4.4-intel-2021.4.0
# module load vasp/6.2.1-intel-2021.4.0-cuda-11.5.0
ulimit -s unlimited
mpirun vasp_std
- 本地编译的 VASP
#!/bin/bash
#SBATCH -J vasp
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
# 导入 oneAPI 套件
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mpi/2021.4.0
module load intel-oneapi-mkl/2021.4.0
ulimit -s unlimited
export OMP_NUM_THREADS=1
export I_MPI_ADJUST_REDUCE=3
mpirun ${HOME}/bin/vasp_std
注:相关命令含义
ulimit -s unlimited
export OMP_NUM_THREADS=1
export I_MPI_ADJUST_REDUCE=3
ulimit -s unlimited- 设置进程的堆栈大小限制。通过指定unlimited,表示将堆栈大小限制设置为无限制。堆栈是用于存储函数调用和局部变量的内存区域,增加堆栈大小限制可以允许进程使用更多的堆栈空间。这对于需要递归调用或者使用大量局部变量的程序可能是必需的。export OMP_NUM_THREADS=1- 设置OMP_NUM_THREADS环境变量,并将其值设为 1。OMP_NUM_THREADS是 OpenMP 库使用的一个环境变量,用于指定并行计算时使用的线程数。在这里,将线程数设置为 1 表示只使用一个线程进行并行计算。这可以用于限制并行化的程度,特别是当希望使用单线程执行时。export I_MPI_ADJUST_REDUCE=3- 设置I_MPI_ADJUST_REDUCE环境变量,并将其值设为 3。I_MPI_ADJUST_REDUCE是 Intel MPI 库使用的一个环境变量,用于调整 MPI 库中用于并行归约操作(reduce operation)的算法。将该变量设置为 3 表示使用性能优化的归约算法。这可以提高 MPI 程序中归约操作的效率。
# LAMMPS
- 思源一号 LAMMPS
#!/bin/bash
#SBATCH --job-name=lmp
#SBATCH --partition=64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH --output=%j.out
#SBATCH --error=%j.err
module purge
module load lammps/20220324-intel-2021.4.0-omp
mpirun lmp -i in.test
- 超算 Pi 新 CPU 队列 LAMMPS
#!/bin/bash
#SBATCH -J lmp_pi
#SBATCH -p cpu
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
module load lammps/20230802-oneapi-2021.4.0
mpirun lmp -in in.test
# Python
#!/bin/bash
#SBATCH -J python
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
conda activate <ENV_NAME>
# source path/activate <ENV_NAME>
python test.py
# Shell
#!/bin/bash
#SBATCH -J bash
#SBATCH -p 64c512g
#SBATCH -N 1
#SBATCH --ntasks-per-node=1
#SBATCH -o %j.out
#SBATCH -e %j.err
module purge
bash test.sh
# 任务状态检查
任务提交后,会生成 jobid.err 和 jobid.out 文件:
err文件为空(大部分情况下),表示提交的任务未出错err文件不为空,表示提交的任务出错;需查看err文件中的出错提示,进行修改- 若
err、out文件出现以下内容,大概率为超算平台出现故障,请与相关负责人联系
# err 文件内容
/tmp/slurmd/jobid/slurm_script: line 24: mpirun: command not found
# out 文件内容
couldn't read file "/usr/share/Modules/libexec/modulecmd.tcl": no such file or directory
# 相关问题
[x]
mpirun和srun的区别是什么?intel 编译套件?srun和mpirun的区别 (opens new window)srun 是 slurm 作业调度系统的一个命令,mpirun 是 mpi(实现形式有 openmpi,mpich,intel mpi 等)的一个命令,两者在效率方面是无法直接比较的。
当你用 slurm 作业调度系统的时候,你可以通过 srun 提交作业,提交的作业如果是 mpi 并行的,那么它会去调用相应的 mpirun 来运行作业,这两个就是这样一个关系
mpirun 用来并行任务
# 数据传输
超算进行数据传输一般在 data 节点上进行。超算传输节点:
# Pi
data.hpc.sjtu.edu.cn
# 思源一号
sydata.hpc.sjtu.edu.cn
# 命令行
主要使用 scp 和 rsync 两个命令:
- scp:Secure Copy,是一种安全的文件传输协议,它使用 SSH(Secure Shell)协议来加密和传输文件。SCP 允许你将文件从一个系统复制到另一个系统,也可以在本地系统和远程系统之间传输文件。它提供了对远程系统的安全访问,并使用类似于 cp(复制)命令的语法来指定源文件和目标位置。
- rsync:可以通过检测源和目标文件之间的差异,仅传输发生更改的部分,从而在网络带宽和传输时间上提供更好的性能。
- scp:
scp -r src_path dest_path
# 将 manager 的数据上传到 master 上
scp -r 1.manager yangsl@master:/home/yangsl/test
# 将 master 的数据下载到 manager 上
scp -r yangsl@master:/home/yangsl/test/1.master .
scp -r [email protected]:/dssg/home/acct-mseklt/mseklt/yangsl/tests/1.sy .
scp -r 1.manager [email protected]:/dssg/home/acct-mseklt/mseklt/yangsl/tests
- rsync:
rsync -avu src_path dest_path
# 将manager的数据上传到master上
rsync -avu 1.manager yangsl@master:/home/yangsl/test
# 将master的数据下载到manager上
rsync -avu yangsl@master:/home/yangsl/test/1.master .
rsync -avu [email protected]:/dssg/home/acct-mseklt/mseklt/yangsl/tests/1.sy .
rsync -avu 1.manager [email protected]:/dssg/home/acct-mseklt/mseklt/yangsl/tests
注:rsync 的部分参数介绍:
a, --archive- 归档模式。保持文件属性和目录结构,并递归地复制子目录。这是最常用的 rsync 选项,相当于rlptgoD。r, --recursive- 递归地复制目录和子目录。l, --links- 处理符号链接。保持符号链接的属性。p, --perms- 保持文件权限。t, --times- 保持文件时间戳。g, --group- 保持文件所属组。o, --owner- 保持文件所有者。D, --devices- 保持设备文件(块设备和字符设备)。v, --verbose- 显示详细输出。在传输过程中显示文件列表。z, --compress- 使用压缩传输。在网络带宽有限时,可以加快传输速度。h, --human-readable- 以人类可读的格式显示输出。文件大小以 KB、MB、GB 等表示。n, --dry-run- 执行模拟运行,不实际进行文件传输或同步。可以用于检查操作的效果。-delete- 删除目标文件夹中与源文件夹不匹配的文件。这将确保目标文件夹与源文件夹完全同步。-exclude- 排除指定的文件或目录,不进行传输或同步。可以使用通配符模式进行匹配。-include- 只包括指定的文件或目录,排除其他文件或目录。可以使用通配符模式进行匹配。e, --rsh=COMMAND- 指定用于远程 shell 的命令。默认为使用 ssh。-u,--update- 仅传输源文件中更新或修改过的文件。使用-u选项可以减少传输的数据量,节省带宽和传输时间。
# 客户端
软件主要使用 WinSCP;免密登录操作见下图:
# manager 与超算间的数据传输
上传与下载:upload 与 download 脚本
- manager 与 Pi:
upload -s P或将P改成H或h - manager 与思源一号:将
P改成s which upload或which download,查看其可执行文件位置与源码内容
upload -s P manager/path pi/path
upload -s s manager/path siyuan/path
download -s P pi/path manager/path
download -s s siyuan/path manager/path
# 程序编译/安装
- 在超算上编译程序,由于登录节点资源有限,需在计算节点上进行,需申请临时计算节点(一个核即可)。
# 思源一号
srun -p 64c512g -n 1 --pty /bin/bash
# Pi
srun -p cpu -n 1 --pty /bin/bash
# 源码编译
编译前,需理解 Makefile 文件中的命令含义!
# 自定义安装路径
./configure --prefix=
# 编译
make
# 安装
make install
# posconv、NumNei
- posconv:构型文件格式转换(POSCAR、xyz、LAMMPS atomic/dump、Material Studio 等)
- NumNei:计算 BCC、FCC 和金刚石结构的第 N 近邻原子距离
- 编译:编译器可选择 gfortran 或 ifort(gfortran 已足够;ifort 性能可能更好些)
posconv 的 LAMMPS dump 格式原子坐标为分数坐标,即为 xs, ys, zs
# latgen
- 构型生成程序,包括 BCC、FCC、HCP、diamond、含点缺陷、置换固溶体、表面等构型。
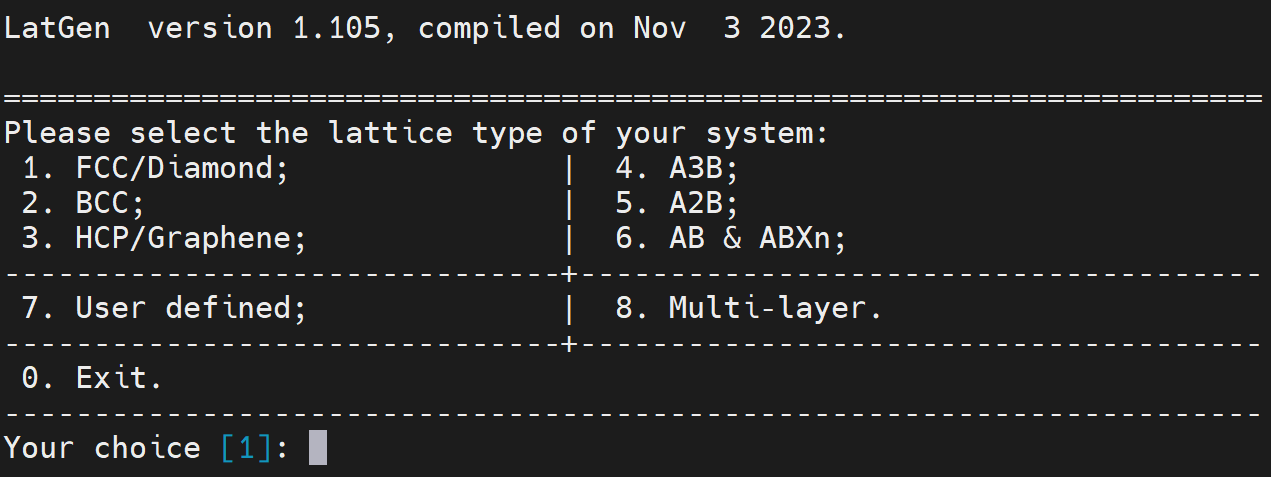
编译:依赖 voro++;编译器可选择 gcc 或 icc
- voro++ 编译
wget https://math.lbl.gov/voro++/download/dir/voro++-0.4.6.tar.gz
tar -xzvf voro++-0.4.6.tar.gz
cd voro++-0.4.6.tar.gz
# 修改 config.mk 的 PREFIX 选项
PREFIX=${HOME}/src/voro++
make && make install
- 修改 latgen 中的 Makefile 文件内容(
INC:voro++ 的头文件路径;LIB:库路径)
VoroINC = -I${HOME}/src/voro++/include/voro++
VoroLIB = -L${HOME}/src/voro++/lib -lvoro++
# dumpana
- LAMMPS dump 文件后处理程序。可以计算:CSRO;RDF、PDF、g(r) (径向分布函数);扩散系数;键长键角;混合构型熵;局域序参数等
- dumpana、latgen、posconv 和 vaspkit 等程序都可以通过
latgen < inp.script命令,使其不用每次交互输入参数,节约时间(重要!!!)。
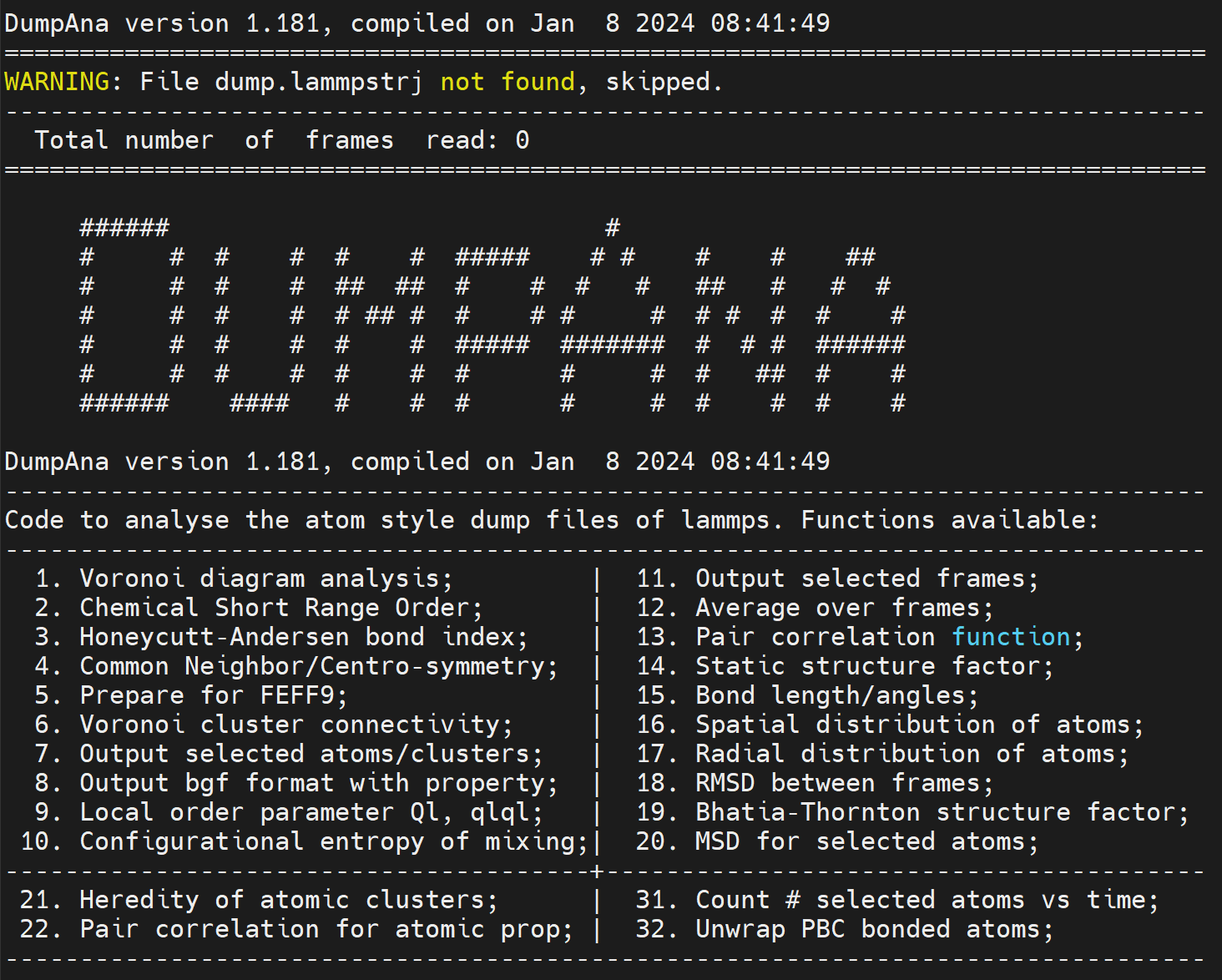
编译:编译依赖 voro++ 和 gsl(C 数值计算库);编译器可选择 gcc 或 icc
- gsl 编译
wget https://mirror.ibcp.fr/pub/gnu/gsl/gsl-latest.tar.gz
./configure --prefix=${HOME}/src/gsl
make && make install
# 将 gsl 的 lib 路径添加到 LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$HOME/src/gsl/lib:${LD_LIBRARY_PATH}
- master 平台编译
修改 Makefile 文件内容(voro++、gsl 的 INC 和 LIB),编译
VoroINC = -I${HOME}/src/voro++/include/voro++
VoroLIB = -L${HOME}/src/voro++/lib -lvoro++
GslINC = -I${HOME}/src/gsl/include
GslLIB = -L${HOME}/src/gsl/lib -lgsl -lgslcblas
# master 上有 voro++、gsl;可不用修改
VoroINC = -I/opt/libs/voro/include/voro++
VoroLIB = -L/opt/libs/voro/lib -lvoro++
GslINC = -I/opt/libs/gsl/include
GslLIB = -L/opt/libs/gsl/lib -lgsl -lgslcblas
- 思源一号平台编译
git clone https://github.com/lingtikong/dumpana.git
module purge
module load gsl/2.7.1-intel-2021.4.0
module load intel-oneapi-compilers/2021.4.0
# 编译器选择 icc
# 修改 Makefile 文件的 voro++ 内容,gsl 可不用修改
make
若使用时报错,设置 gsl 相关的动态链接库文件的软链接
ln -s /dssg/opt/icelake/linux-centos8-icelake/intel-2021.4.0/gsl-2.7.1-363bjoc7gmwz4mpn2csc7paszwv5h2wk/lib/libgsl.so.27 ~/lib/
ln -s /dssg/opt/icelake/linux-centos8-icelake/intel-2021.4.0/gsl-2.7.1-363bjoc7gmwz4mpn2csc7paszwv5h2wk/lib/libgslcblas.so.0 ~/lib/
# atomsk
- 结构建模程序;同 latgen 相比,可生成孪晶、晶界、位错、层错等更多复杂构型
- 示例丰富,文档详细
安装:Atomsk - Install - Pierre Hirel (opens new window)
下载二进制版本(最简单方式):Download Atomsk (opens new window)
源码编译:
依赖 BLAS 和 LAPACK 库(manager/master/超算上没有这两个库,需源码编译;LAPACK 依赖 BLAS;intel 套件有相关库)
编译 BLAS 和 LAPACK 步骤以及压缩包:
LAPACK build and test guide - GNU Project (opens new window)
创建 ~/lib,并将其添加到 LD_LIBRARY_PATH;将 *.a 静态库文件设置软链接(或复制)到此
export LD_LIBRARY_PATH=$HOME/lib:$LD_LIBRARY_PATH
编译 BLAS
make
mv blas_LINUX.a libblas.a
cp *.a ~/lib
编译 LAPACK
cp make.inc.example make.inc
make # 这步花费时间会比较长
cp *.a ~/lib
下载 atomsk 源代码,进入 src,修改 Makefile 文件
LAPACK=-L$HOME/lib/ -llapack -lblas
INSTPATH=$HOME/src
CONFPATH=${INSTPATH}/etc
编译:
make atomsk
make install # 应该会出错,但没关系,这步非必需
编译成功:
\o/ Compilation was successful!
<i> To install Atomsk system-wide, you may now run:
sudo make install
- 编译 ifort 版本
# 导入 oneapi 套件
module purge
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mpi/2021.4.0
module load intel-oneapi-mkl/2021.4.0
git clone https://github.com/pierrehirel/atomsk.git
cd atomsk/src
make -f Makefile.ifort atomsk
# 超算(思源一号)使用 atomsk 时
# 需设置 libiomp5.so 文件的软链接
# 或使用前 module load intel-oneapi-compilers/2021.4.0
ln -s /dssg/opt/icelake/linux-centos8-icelake/gcc-8.5.0/intel-oneapi-compilers-2021.4.0-rszhbg2vjwqqeddqqdryjwxromenbfmr/compiler/2021.4.0/linux/compiler/lib/intel64_lin/libiomp5.so ~/lib/libiomp5.so
- macOS 编译 atomsk
# 需安装 LAPACK 和 OpenMP(非必需)
# 修改 Makefile.macos 中的 LAPACK lib 路径
# 并将 -lrefblas 改为 -lblas,最后编译
make -f Makefile.macos atomsk
make -j3 -f Makefile.macos atomsk
# VASP.5.4.4
参考:
VASP.5.4.4 源代码目录结构:
arch:针对不同架构的 Makefile 模板,如makefile.include.linux_intelbin:编译后的可执行程序文件目录build:编译时自动复制 src 目录内源码后执行编译的目录src:源码目录lib:库目录,对应以前的 vasp.lib 目录CUDA:GPU CUDA 代码目录
vasp.X.X.X (root directory)
|
---------------------------------------
| | | |
arch bin build src
|
---------------
| | |
lib parser CUDA
- 安装步骤:
- VASP.5.4.4 安装包:manager:
/opt,master:/opt/software;将其拷贝到自己的用户目录下打包压缩,上传至超算平台) - 三种版本可分开进行编译:
make std,make gam,make ncl bin目录若出现vasp_std,vasp_gam,vasp_ncl可执行文件,则表示编译成功;- 将
vasp_std设置软链接
- VASP.5.4.4 安装包:manager:
# 导入 oneapi 套件
module purge
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mpi/2021.4.0
module load intel-oneapi-mkl/2021.4.0
# 删除 bulid 和 bin 目录中的内容
make veryclean
rm bin/*
cp arch/makefile.include.linux_intel makefile.include
# 编译;耗时 20-30 分钟
make # make all
# HDF5
- 安装步骤:
wget https://hdf-wordpress-1.s3.amazonaws.com/wp-content/uploads/manual/HDF5/HDF5_1_14_3/src/hdf5-1.14.3.tar.gz
# 配置 intel 版本
./configure --enable-parallel --enable-fortran --enable-cxx --enable-unsupported \
CC=mpiicc FC=mpiifort CXX=mpiicpc \
--prefix=${HOME}/local/hdf5
make
make install
未添加 --enable-parallel 参数会出现以下报错:
configure: error: --enable-cxx and --enable-parallel flags are incompatible. Use --enable-unsupported to override this error.
# 显示 HDF5 的编译和配置详细信息
h5cc -showconfig # 或 h5c++ h5pcc
# 显示用于编译 HDF5 的编译器命令行,包括链接的库和编译器标志
h5cc -show
- 使用
- HDF5 Preview 插件:只能打开.hdf5 格式,无法打开.h5 格式
- Pandas 的 read_hdf() 不太好用
h5ls data.h5 # 显示 Group 列表
# vaspout.h5 示例
input Group
intermediate Group
original Group
results Group
version Group
h5dump data.h5 # 输出文件的详细结构和内容
# VASP.6.3.0 + HDF5
VASP.6.3.0 源代码目录结构:
vasp.x.x.x (root directory)
|
------------------------------------------------
| | | | | |
arch bin build src testsuite tools
|
-------------
| | |
lib parser fftlib
- 安装步骤:master 的 vasp.6.3.0 安装包在
/opt/software下;将其拷贝到自己的目录下打包,上传至超算平台)
# 导入 oneapi 套件;hdf5
module purge
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mpi/2021.4.0
module load intel-oneapi-mkl/2021.4.0
module load hdf5/1.12.2-intel-2021.4.0
# 查看 hdf5/1.12.2-intel-2021.4.0 的安装路径
module show hdf5/1.12.2-intel-2021.4.0
cp arch/makefile.include.intel makefile.include
# 删除 MKLROOT ?= 后的内容 此步可忽略
# 取消 HDF5 相关行注释,将 HDF5_ROOT ?= 后的内容替换为 hdf5 的安装路径
make # 或 make all, make std
可能会出现以下报错:
error while loading shared libraries: libhdf5_fortran.so.102: cannot open shared object file: No such file or directory
原因:缺少 libhdf5_fortran.so.102 动态链接库,其实 module load 的 hdf5/1.12.2-intel-2021.4.0 有该动态链接库,不过版本更新一些,为 libhdf5_fortran.so.200
解决方法:将 libhdf5_fortran.so.200 软链接为 libhdf5_fortran.so.102;将 ~/lib 写入到 LD_LIBRARY_PATH
ln -s /dssg/opt/icelake/linux-centos8-icelake/intel-2021.4.0/hdf5-1.12.2-nxwmp3tddhreojgbib25ldc7wusvzf3m/lib/libhdf5_fortran.so.200 ~/lib/libhdf5_fortran.so.102
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HOME/lib
# VASP + VTST
VASP + VTST:在 VASP 添加过渡态计算功能
参考:Installation — Transition State Tools for VASP (opens new window)、VASP 5.4.1+VTST编译安装 (opens new window)
安装步骤:
下载 VTST Code 和 VTST Scripts:Download — Transition State Tools for VASP (opens new window)
修改
src/main.F源码:
# 替换前
CALL CHAIN_FORCE(T_INFO%NIONS,DYN%POSION,TOTEN,TIFOR, &
LATT_CUR%A,LATT_CUR%B,IO%IU6)
# 替换后;添加了 TSIF,
CALL CHAIN_FORCE(T_INFO%NIONS,DYN%POSION,TOTEN,TIFOR, &
TSIF,LATT_CUR%A,LATT_CUR%B,IO%IU6)
# vasp.6.2 及以后,还需进行以下替换
# 替换前
IF (LCHAIN) CALL chain_init( T_INFO, IO)
# 替换后
CALL chain_init( T_INFO, IO)
- 备份
src/chain.F;复制 vtstcode-XXX 中对应 VASP 版本(如 vtstcode5、vtstcode6.3;vtstcode6.3 中多了ml_pyamff.F文件和pyamff_fortran/目录)的目录下的所有文件到src/:
cp src/chain.F src/chain.F-org
cp vtstcode-XXX/vtstcodeXXX/* src/
- 修改
src/.objects源码,在chain.o所在行前添加:
# vtstcode5 和 vtstcode6.1
bfgs.o dynmat.o instanton.o lbfgs.o sd.o cg.o dimer.o bbm.o \
fire.o lanczos.o neb.o qm.o opt.o \
# vtstcode6.3
bfgs.o dynmat.o instanton.o lbfgs.o sd.o cg.o dimer.o bbm.o \
fire.o lanczos.o neb.o qm.o \
pyamff_fortran/*.o ml_pyamff.o \
opt.o\
- 使用 vtstcode6.3,还需修改
src/makefile源码:
# 替换前
LIB= lib parser
dependencies: sources
# 替换后
LIB= lib parser pyamff_fortran
dependencies: sources libs
- 编译:同 VASP 编译步骤
# LAMMPS
使用 cmake 编译
wget https://download.lammps.org/tars/lammps-2Aug2023.tar.gz
tar -xzvf lammps-2Aug2023.tar.gz
cd lammps-2Aug2023
# 导入 oneAPI 套件
module purge
module load intel-oneapi-compilers/2021.4.0
module load intel-oneapi-mkl/2021.4.0
module load intel-oneapi-mpi/2021.4.0
# 建议再导入该 oneAPI 模块
module load intel-oneapi-tbb/2021.4.0
# 编译配置
mkdir build && cd build
# C++ 等编译器均为 GNU套件的
cmake -C ../cmake/presets/most.cmake ../cmake
# oneapi 可替换成 intel
# oneapi IntelLLVM C++ 编译器为 intel oneapi 的 icpx
# intel Intel C++ 编译器为 intel oneapi 的 icpc
cmake \
-C ../cmake/presets/most.cmake \
-C ../cmake/presets/oneapi.cmake \
../cmake
# 编译
make # cmake --build .
# vaspkit
- VASP 预、后处理工具;Overview — VASPKIT 1.5 documentation (opens new window)
- 预处理:不同计算任务的输入文件生成与检验;结构对称性分析等
- 后处理:力学性质;能带;态密度;费米面分析等
- 安装:在 vaspkit - Binaries (opens new window) 中下载 vaspkit 最新版本,解压,拷贝配置文件,对可执行文件设置软链接
cp how_to_set_environment_variables ~/.vaspkit
# 修改以下参数
PBE_PATH
VASPKIT_UTILITIES_PATH
PYTHON_BIN # 可选
- 赝势:可拷贝 master 或 manager 上的赝势上传到超算自己的用户目录下;赝势格式如下:
pseudopotentials
├── lda_paw
│ ├── Ag
│ │ ├── POTCAR
│ │ └── PSCTR
vaspkit -help # 查看帮助
vaspkit # 进入交互模式
vaspkit < XXX.in # 推荐此命令,适用于批处理
echo -e "102\n2\n0.04\n" | vaspkit
- vaspkit.1.5.0.Mac.Intel 版本可以在 Mac M1 上运行
# phonopy
安装
conda install -c conda-forge phonopy
pip install -U phonopy
# sqsgen
- 安装:How to install sqsgen? — sqsgenerator 0.2 documentation (opens new window)
- 命令行使用:CLI reference — sqsgenerator 0.2 documentation (opens new window)
- 多亚点阵 sqsgen 生成示例:Advanced topics — sqsgenerator 0.2 documentation (opens new window)
sqs 生成程序
- 目标函数为 WC 参数;
- 生成速度相比 ATAT 及 ICET 相关模块要快,功能也更多;
- 10000 个原子构型的 sqs 生成速度在 2min 以内;
- 可事先估计生成 sqs 结构所耗费时间;可计算 WC 参数等;
- 浓度用具体的原子数目表示,比百分比形式更方便;
- 有 OpenMP 和 OpenMP+MPI 两种版本。
conda 版本(OpenMP 版本)
conda create --name sqsgen python=3
conda install -c conda-forge sqsgenerator
# 导出构型文件需要以下 package
pip install pymatgen ase
编译版本(OpenMP+MPI)
conda create --name sqsgen -c conda-forge boost boost-cpp cmake gxx_linux-64 libgomp numpy pip python=3
git clone https://github.com/dgehringer/sqsgenerator.git
- OpenMP 版本
conda activate sqsgen
cd sqsgenerator
SQS_Boost_INCLUDE_DIR="${CONDA_PREFIX}/include" \\
SQS_Boost_LIBRARY_DIR_RELEASE="${CONDA_PREFIX}/lib" \\
CMAKE_CXX_COMPILER="g++" \\
CMAKE_CXX_FLAGS="-DNDEBUG -O2 -mtune=native -march=native" \\
pip install .
- OpenMP+MPI 版本
conda activate sqsgen
cd sqsgenerator
SQS_MPI_HOME="${HOME}/yangsl/src/openmpi" \\
SQS_USE_MPI=ON \\
SQS_Boost_INCLUDE_DIR="${CONDA_PREFIX}/include" \\
SQS_Boost_LIBRARY_DIR_RELEASE="${CONDA_PREFIX}/lib" \\
CMAKE_CXX_COMPILER="g++" \\
CMAKE_CXX_FLAGS="-DNDEBUG -O2 -mtune=native -march=native" \\
pip install .
# texlive
- texlive 版本:思源一号 2018;pi 2013;manager 2015;master 未安装;无 root 权限,无法安装 package
- 可自定义安装路径
- texlive 不同版本需要安装的 packages 数目:medium 约 1395 项;full 约 4543 项。
# 添加 自定义安装路径 环境变量
export TEXLIVE_INSTALL_PREFIX=$HOME/src/texlive
export TEXLIVE_INSTALL_TEXDIR=$HOME/src/texlive/2023
# 安装
wget https://mirror.ctan.org/systems/texlive/tlnet/install-tl-unx.tar.gz --no-check-certificate
tar -xzvf nstall-tl-unx.tar.gz
cd install-tl-*
# medium 或 small
perl ./install-tl --scheme=full
# 不进行交互
# perl ./install-tl --scheme=full --no-interaction
# 安装完成后,再添加环境变量
export MANPATH=$HOME/src/texlive/2023/texmf-dist/doc/man
export INFOPATH=$HOME/src/texlive/2023/texmf-dist/doc/info
export PATH=$HOME/src/texlive/2023/bin/x86_64-linux:$PATH
# ATAT
WIP…
# 交我算常见问题总结
以下是使用 “ 交我算 ” 过程中可能遇到的常见问题总结:
充值/费率
- 计费系统 (HPC 账号和密码登陆):https://account.hpc.sjtu.edu.cn (opens new window)
- 充值方法:https://net.sjtu.edu.cn/info/1244/2392.htm (opens new window)
- 费率问题:请用交大邮箱发送至 [email protected] 咨询
致谢模版
- “ 交我算 ” 用户在发布科研成果或论文时,应标注 “ 本论文的计算结果得到了上海交通大学交我算平台的支持和帮助 “(The computations in this paper were run on the π 2.0 (or Siyuan Mark-I) cluster supported by the Center for High Performance Computing at Shanghai Jiao Tong University). 论文发表后,欢迎将见刊论文通过邮件发送到 [email protected]。
登录问题
- 连不上集群: https://docs.hpc.sjtu.edu.cn/faq/index.html#id6 (opens new window)
- 登录常掉线:https://docs.hpc.sjtu.edu.cn/login/index.html#id10 (opens new window)
- HPC studio 登录问题:https://docs.hpc.sjtu.edu.cn/studio/faq.html#hpc-studio-proxy-error (opens new window)
- Jupyter、Rstudio 连接提示需要输入密码:https://docs.hpc.sjtu.edu.cn/studio/faq.html#jupyterrstudio (opens new window)
排队问题
- status 监控系统:https://status.hpc.sjtu.edu.cn (opens new window),该系统包含各队列上线节点数、排队数、作业数等信息
- π集群排队问题:思源一号可用 CPU/GPU 资源更多,欢迎使用思源一号。
- 通过 squeue 查看作业,NODELIST(REASON) 为 resources/priority 表示正常排队,AssocGrpNodeLimit 表示欠费。
作业问题
- 报错作业咨询,请将用户名、作业 ID、路径、作业脚本名邮件发至 [email protected]。
- NodeFail:计算节点故障导致作业运行失败,重新提交作业即可,失败作业的机时系统会自动返还。
- 运行程序时提示缺少 xxx.so 文件或者显示任务被 kill:如果是在登录节点出现该报错,请申请计算节点再做尝试。
软件安装问题
- 如何在集群上安装软件:https://docs.hpc.sjtu.edu.cn/faq/index.html#id16 (opens new window)
- 商业软件问题:https://docs.hpc.sjtu.edu.cn/faq/index.html#id17 (opens new window)
数据传输问题
常用链接